이 논문은 CVPR'22에 publish된 논문으로 2023.12.21 기준 76회의 citation을 보유하고 있다.
이전에 리뷰했던 논문 TraDeS 처럼 Joint Detection and Tracking (JDT) 논문인데, association을 위해서 transformer를 사용하였다. 이전에 리뷰했던 TrackFormer (CVPR'22), MOTR (ECCV'22) 등과 굉장히 유사한데, 사람생각하는게 다 비슷한지 이때쯤 Transformer로 association을 시키는 유행히 돌았던 것 같다. 세부적인 loss, implementation details, training heuristics는 다를 수 있겠지만, 개인적으로 TrackFormer와 거의 동일한 것 같고,,, group (32 frames)에 대해 동시에 parallel prediction & supervision을 준다는 약간의 차이가 있는 것 같다.
논문은 https://arxiv.org/abs/2203.13250 에서 찾아볼 수 있고, 코드는 https://github.com/xingyizhou/GTR 에 있다. 😉
Introduction
먼저, 이 논문은 기존의 MOT methods 들이 다음의 한계가 있다고 지적한다.
(1) Tracking by Detection (TbD) 의 local tracker : 보통 Kalman filter 등에 의존해서 바로 직전 frame에 있는 object와 현재 frame의 obejct을 associate하는데 occlusion이나 motion blur에 취약한 단점이 있다. (10~20 frames 이전을 못봐서..)
(2) Graph 기반의 offline tracker : 성능이 좋긴한데, 학습이 오래걸리고 detector와 detached 되어 있는 단점이 있다.

저자들은 위 works의 단점을 보완하기 위해 GTR (Glbao TRacking transformer)를 제안하였는데...
1) TbD 처럼 two-stage 방식이 아니라 end-to-end training이 가능하고,
2) Local tracker와 달리 여러 frame의 정보를 동시에 고려할 수 있고,
3) SoTA detector (detector of QDTack) 에 integrate 하여 성능 향상을 보였고,
4) MOTR, DETR의 object query로 learnable fixed feature라 아니라 이전 frame의 object features를 썼다고 한다.
Method : GTR
알고리즘 overview 에 대한 설명은 아래 figure를 참고하면 약간 도움이 된다. 솔직히 너무 대충 그렸다. 가장 중요한 Global Tracking Transformer를 blackbox 처리하는게 말이 되는가?
위의 "All-frame detections"를 key, "Trajectory queries"를 query 라고 생각하면 된다.
value 가 뭔지 나도 참 궁금한데 이 논문 통틀어서 value라는 단어는 한번도 등장하지 않는다. .🤦♂️🤦♀️🤦♂️🤦♀️
Tracking transformer. TraDeS와 다르게 GTR은 detection을 먼저 수행한다. 👉 이후 detected box의 features (아래 F, Q)를 가지고 key, query를 만들어 transformer에 통과시키고 association probability (아래 G) 를 얻어내는 순서로 진행된다.
Query : current t frames의 object features (위 그림에서 M은 한 frame내 object의 개수)
Key : 이전 T frames (t−1,t−2,...,t−T) 의 object features (위 그림에서 N은 이전 T frames의 모든 object 개수)
Value : 논문에서 알려주지 않음 🤦♂️🤦♀️
GTR output : association score (G)
👉 예를 들어서 Gi,j는 i 번째 past object와 j 번째 current object 가 얼마나 associate할만한지... 를 나타낸다.
👉 이 score는 현재 frame에 등장하는 모든 object에 대하여 softmax normalization을 거쳐 확률의 형태로 변환된다.
👉👉 Background에 대응되는 특별한 query (learnable인지는 모르겠음) 이 존재한다.
👉 위 equation에서 i 는 current frame의 object index이고, k는 trajectory의 ID index이다.
👉 위 equation에서 F={Ft−T+1,...,Ft} 는 past frames의 object features인데 current frame의 feature를 포함한다!!
(i는 current frame의 object index인데,,, 위 equation에서 i가 key에 대응되고, k가 query에 대응될 것이다)
(위 architecture figure에서 G의 모양이 M x N 이고 k∈{1,...,M} 일텐데... 그럼 i∈{1,...,N} 이어야겠지..?)
🤔 그럼 위 equation에서 PA(\alptat=i|qk,F) 가 의미하는 뜻은?
😃 past object features F을 key로, current t frame의 kth GT features qk 를 query로 Tracking transformer를 통과시켰을때 얻은,,,,, kth query와 ith object (in t frame) 사이 association probability. (어렵다 어려워! 🤦♂️)
Training of GTR. Loss를 만드려면 prediction과 ground truth를 match 해야하는데,, classification과 달리 detection, tracking works은 이 과정이 참 고약하다 (한 이미지 안에 여러 pred와 여러 GT가 존재하므로..🤔)
이 work에서는 pred와 GT의 IoU가 0.5이상이면 match 시키고 그렇지 않으면 false positive로 간주한다.
👉 한 pred가 여러 GT에 match 되거나, 한 GT에 여러 pred가 match 될 수 있다.
그리그리하여,, tracking transformer를 학습시키는 association loss는 아래와 같다.
😀 하나하나 풀어서 해석하면.. (1) past object features F을 key로, (2) kth trajectory를 따르는 s frame의 foreground object feature $F_{\hat{alpha^{s}_k}^s$를 query로 Tracking transformer를 통과시켰을때 (3) t frame에서 kth trajectory에 대응되는 objects들의 (4) association probability를 maximize 시킨다. (어렵다 어려워! 🤦♂️)
😬 주의할점! (5) t는 key 에 대한 frame index이고, (6) s는 query 에 대한 frame index이다..!!
위 loss는 foreground predictions들을 supervise 하는 loss이고,,, background predictions에 대한 loss는 아래와 같다.
위 foreground loss랑 비슷한 형태인데,,, 위와 달리 대응되는 GT가 없을 때 BG prediction을 강화시킨다.
위의 loss가 final loss인데 transformer에 key로 아무 features나 넣지 않고, 특정 trajceteory의 것만 넣는게 신기하다.
Connection to embedding learning and Re-ID. 만약 assocation probability를 계산할 때 (1) transformer 대신 key와 query 사이 inner product를 사용하고,, (2) 위 PA(\alptat=i|qk,F) 처럼 features에 대해 softmax를 취하지 않는다면 기존의 Re-ID 방식과 비슷해진다고 한다... (🤔 흠.. 방금 빠르게 FairMOT 보고 왔는데 잘 모르겠다..)
아무튼 GTR은 기존의 Re-ID 방식보다 다음의 장점이 있다고 한다.
(1) Transformer 구조를 사용해서 모든 frames의 모든 object에 대해서 한번에 PA(\alptat=i|qk,F)를 계산할 수 있다.
(2) DETR, MOTR 처럼 queries를 학습해서 사용할 필요가 없다. (그냥 object feature를 넣으면 된다.)
Experimental Results
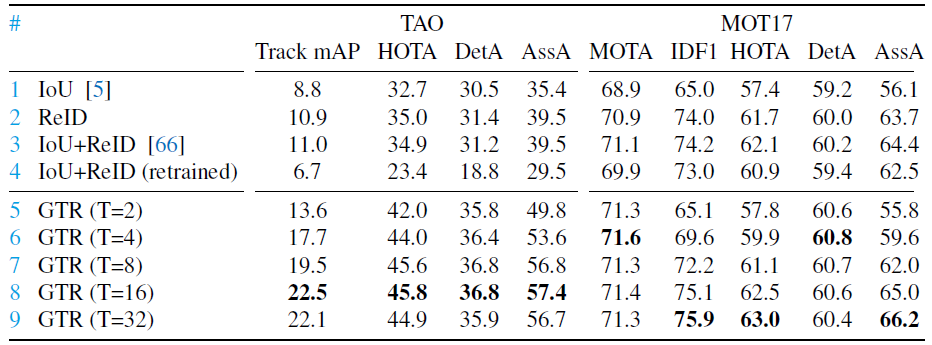
위 Figure에서 row 1~5는 local tracker, 6~9는 global tracker이다. Local tracker보다는 Glbobal tracker가 있고,, 대체로 buffer memory (T)를 증가시킬수록 성능이 향상되는 것을 볼 수 있다.
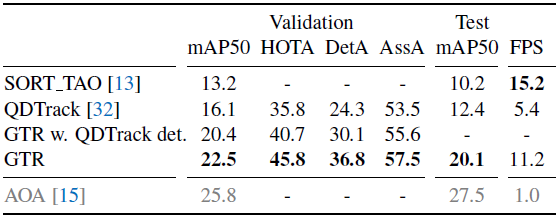
다른 SoTA tracker (QDTrack) 의 detector (애매한데...🤔) 결합해도 성능이 잘 나온다고 한다.
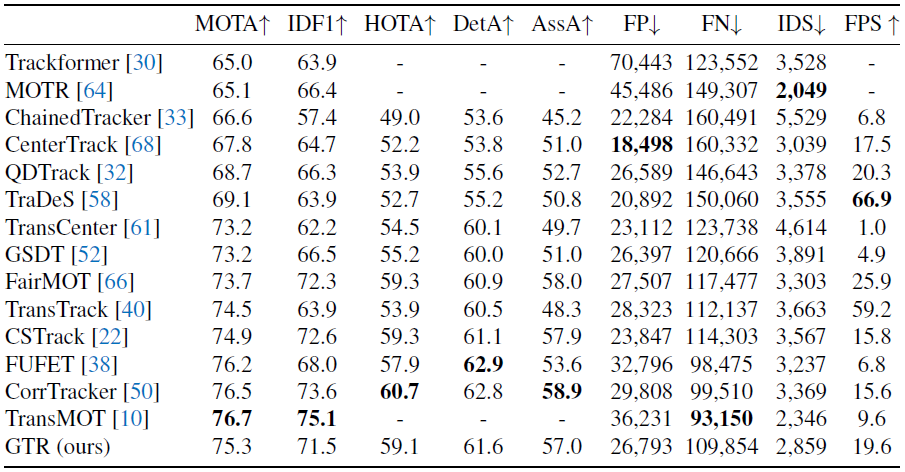

(a) Transformer 구조를 사용하는게 도움이 된다.
(b) Transformer에 positional encoding 할 필요 없다.
(c) Transformer layer 개수는 한개면 충분하다.
(d) 뭔지 모르겠다. (히히! 😀)
이번 논문은 너무 불친절해서 특히 공부가 힘들었다.. ㅠㅠ
이상 끝!! 💪😀🤜
'Object Tracking 공부' 카테고리의 다른 글
| TraDeS : Track to Detect and Segment, An Online Multi-Object Tracker 논문 공부 (0) | 2023.12.19 |
|---|---|
| ByteTrack: Multi-Object Tracking by Associating Every Detection Box 논문 공부 (0) | 2023.12.12 |
| MOTR: End-to-End Multiple-Object Trackingwith Transformer 논문 공부 (0) | 2023.12.01 |
| GHOST: Simple Cues Lead to a Strong Multi-Object Tracker 논문 공부 (0) | 2023.11.30 |
| SiamMOT: Siamese Multi-Object Tracking 논문 공부 (0) | 2023.11.27 |



