이 논문은 CVPR'23에 publish 된 따끈따끈한 논문이다
South China 대학에서 나온 논문이며, https://github.com/Yushu-Li/OWTTT. 에서 코드도 확인할 수 있다.
[논문 요약]
* (거의 처음으로) open-world test-time training (TTT)를 다루었다.
* Evaluation과 model update가 번갈아 진행되는 sequential TTT (sTTT)를 다루었다.
Introduction
기존의 unsupervised TTT methods들은 target domain의 samples이 사전에 다 존재하는 off-line setting이 많았다. 하지만 실제 상황에서는 inference stage에 도달하기 전까지 target domain data가 available 하지 않는 상황이 많다고 한다. 또 이전의 work에서는 잘 다루어지지 않았지만, source domain과 target domain의 category가 일치하지 않는 open-world setting또한 중요하다고 한다. (저자는 class가 다른 경우를 strong-OOD라 하고, 단순 corruption은 weak-OOD라 하였다.)

저자는 위 figure와 같이 기존의 유명한 TTT methods (self-training 방식, distribution alignment 방식 등)이 strong-OOD setting에서 성능이 크게 감소하는 것을 보였다. 그 이유로는 1) self-training 방식은 OOD samples을 source class로 pseudo-labeling하였고, 2) domain alignment method도 strong OOD samples의 distribution을 잘 유추해내지 못했다고 한다. 이 문제들을 해결하기 위해 저자가 내놓은 알고리즘의 큰 특징은 다음과 같다.
[1] prototype clustering 기반의 self-training 기법을 사용한다. 다시말해, target domain sample들을 이미 알고있는 source domain prototype 쪽으로 끌어당긴다는 뜻이다. 이때. 잘못된 pseudo-labeling에 대응하기 위해서 thresholding을 통해 strong OOD samples들을 걸러낸다고 한다. (아래 그림과 같이, strong OOD는 거르고 weak OOD는 사용하는 듯 하다) 추가적으로, TTT가 진행되는 동안 dynamic하게 prototype pool (source & target)을 update한다고 한다.
[2] source domain 과 target domain 사이 distribution alignment를 수행한다. 구체적으로 weak OOD samples과 source domains 사이를 좁히는데, weak OOD samples과 strong OOD samples의 차이를 분명히 해준다고 한다.
[3] open-world TTA benchmark을 만들었다. 아래그림처럼 CIFAR10이 source domain일때, CIFAR10-C를 weak OOD, MNIST를 strong OOD 로 취하는 scenario를 제안하였다.
Related Work
methodology로 들어가기에 앞서 TTA가 정확히 무엇을 하는지, 다른 task와는 어떻게 다른지를 짚고 넘어가도록 하자.
[1] Unsupervised Domain Adaptation (UDA) : target domain의 label을 사용하지 않고 adaptation을 수행한다. 이때 source domain의 data나 statistics 등을 사용할 수 있고 off-line 방식이다.
[2] Source-Free Domain Adaptation (SFDA) : 위의 UDA와 비슷하나, source domain의 데이터를 일절 사용하지 않는다.
[3] Test-Time Training (TTT) : Test-Time Adaptation (TTA)와 같음. SFDA와 비슷한 setting이지만 on-line setup에서 이루어진다. 다시말해, evaluation을 진행하면서 model update가 함께 동반되는 setup인것 같다. 기존의 TTT는 크게 세가지 방향으로 연구가 진행되었다고 한다: self-supervised learning, self-training, distribution-alignment
하지만 기존의 연구는 small-batch TTT, imbalance TTT, open-world TTT 의 경우 성능 하락을 보이고, 제안된 알고리즘은 이 문제들을 해결할 수 있다고 한다.
Methodology
크게 1) prototype clustering 과 2) distribution alignment로 구성된다.
[1] TTT by Prototype Clustering (self-training)
Source domain의 prototype을 사용하여 target domain data를 supervise함과 동시에, target prototype을 discover한다.
Source domain의 category Cs에 대응되는 source prototype pk들을 미리 준비해놓고, target domain의 sample feature들이 pseudo label에 매칭된 source prototype에 가깝게 embed 되도록 loss가 구성된다.
<주의!> 사실 이 알고리즘은 아래 loss를 쓰지 않는다. 이후 나오겠지만 target prototype도 고려된 loss를 사용한다!
사실 위의 loss는 clsed-world TTT 에서 이미 많이 쓰고, 성능도 검증된 알고리즘이다. 하지만 open-world TTT에서는 strong OOD samples들이 존재하기 때문에, 엉뚱한 샘플들이 source prototype으로 끌려올 수 있어 성능이 감소한다. 따라서, 이 논문은 strong OOD score라는 걸 정의해서 일정 threshold 보다 OOD score가 높은 샘플들을 filtering하고 weak OOD samples이라고 예상되는 target domain samples에만 self-training을 수행한다고 한다.
그렇다면 strong OOD score와 threshold는 어떻게 정의해야할까?
[1] strong OOD score 구하기 : source prototype과의 거리의 반비례하기 정의된다. 즉, 멀수록 OOD score가 높다.
[2] threhols value 구하기 : 저자는 target data의 OOD scores 분포가아래 figure처럼 bimodal distribution을 이룰것이라고 가정했다. 사실 이는 저자가 open-world setting을 구현할때 weak OOD 와 strong OOD dataset을 각각 하나씩 섞었기 때문에 가능한 접근법이다. 하지만 현실적인 상황에서 target domain data가 multi-modal distribution이 따를 것을 고려했을때, 이 논문이 methods들은 굉장히 ad-hoc하고 impractical할 것이라 예상할 수 있다. (내가 리뷰어였다면 accept을 주진 않았을듯..) 여하튼, 저자는 아래 minimization 문제를 풀어 threshold (τ)를 계산했는데, weak/strong OOD samples 각각의 입장에서 샘플으로부터 평균 값까지의 거리 제곱을 최소화시키는 문제이다.
[2] Prototype Expansion (Prototype Clustering with Strong OOD Prototypes)
위의 prototype clustering 알고리즘이 잘 동작하려면 weak OOD와 strong OOD 사이의 구별이 잘 되야한다는 조건이 있다. 이를 만족시키기 위해 strong OOD를 잘 discriminate할 수 있는 feature extractor를 학습시키도록 LPC를 개선한다.
기존의 loss에다 strong OOD를 구분하는 loss term 하나가 추가되었다. 자세히 보면 l∈Cs+1을 확인할 수 있는데 이게 무슨 뜻일까? strong OOD data에 대해 label을 전혀 모른다는 가정을 생각해보면, 기존에 알고 있던 특정 class의 prototype을 사용하여 supervision을 주는 것은 불가능하다. 그래서 loss를 어떻게 개조했냐면..!
1) source domain, 이미 prototype을 갖고 있는 target domain category 에 둘다 속하지 않는 데이터의 feature를 prototype으로 간주하고 적당히 긴 Queue에다가 저장 (이걸 prototype queue라 불렀다)
2) test sample이 들어오면 similarity 기반 classification을 통해 source data인지 target data인지 구별
3) 만약 target data라면 feature가 모든 source prototype과 멀어지도록 K+1 classification loss를 구성
[3] Distribution Alignment Regularization
위의 Prototype clulstering은 결국 self-training 기법이라 incorrect pseudo labeling에 취약하다 (confirmation bias). 그래서 이 bias를 완화하기 위해서 안전책으로 distribution alignment를 동시에 수행한다고 한다. 구체적으로는, source domain과 target domain 데이터의 분포를 Gaussian distribution으로 예측하고, 두 gaussian 사이에 KLD loss를 준다고 한다.
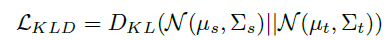
<Algorithm>
Open-word TTT는 online 방식이라 모델 성능을 측정하는 inference stage와 모델을 update하는 adaptation stage가 batch 마다 번갈아가면서 진행된다. 상당히 time-consuming 할 것 같기는 하다.




