이 논문은 ICCV'23에 publish된 논문으로 2023.11.28 기준 1회의 citation을 보유하고 있다.
논문은 https://openaccess.thecvf.com/content/ICCV2023/html/Segu_DARTH_Holistic_Test-time_Adaptation_for_Multiple_Object_Tracking_ICCV_2023_paper.html 에서 찾아볼 수 있고, 코드는 https://github.com/mattiasegu/darth 에서 찾아볼 수 있다.
Introduction
이 논문은 MOT에다가 (자칭) Test-time adaptation을 최초로 접목시킨 논문이다. 기존에 source data를 사용해서 unsupervised adaptation을 푼 논문들은 좀 있었지만, source model 만 가지고 (source data 사용 x) TTA를 푸는 논문은 이게 처음이라고 한다. Object detection에 사용되던 TTA 알고리즘이 몇개 있기는 한데 association, occlusion, re-identification 등의 MOT 요소때문에 object detection 에서 사용되던 TTA 알고리즘을 쉽게 extend 할 수 없다고 한다. 😉

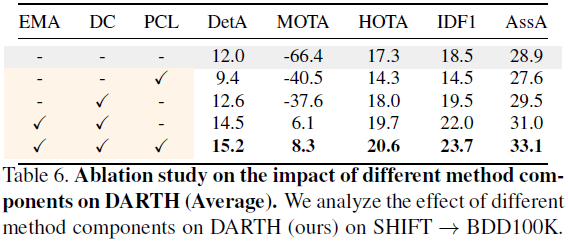
위 figure는 SHIFT에서 학습된 tracker를 BDD100K에 adapt 시킨 경우의 예시인데, 아무런 adaptation을 적용하지 않았을 경우, ID switch 가 빈번하게 발생하는 것을 관측할 수 있다. (아마 classification acc. 도 많이 낮을 것이다). 저자들은 위 TTA를 성공시키기 위해 DARTH를 제시하였고, technical 하게는 (1) QDTrack을 기반으로 하고, (2) exponential moving average (EMA)로 구한 teacher로부터 (3) detection consistency loss와 (4) patch contrastive loss를 계산해 TTA를 수행한다. Contributions 을 요약하자면 (i) MOT에서 domain shift가 어떻게 나타나는지를 보였고, (ii) 두가지 loss를 제안하였다.
Method - Overview
본격적으로 loss에 대해 공부하기 전에 두가지 알고 넘어가야할 정보가 있다.
Architecture. DARTH는 QDTrack을 기반으로하고, 두개의 proposed loss중 하나인 Patch Contrastive Loss는 사실상 QDTrack 의 quasi-dense similarity training과 크게 다르지 않다 (다른 점이 있다면 teacher가 추가되었다는 정도..)
DARTH의 teacher는 exponential moving average (EMA)로 계산되고, student view와 contrastive view에게 positive/negative pair를 구하는데 도움을 준다. QDTrack이 Faster-RCNN을 기반으로하다보니 이 논문도 RPN이나 RoI feature 같은 개념이 많이 나온다 (아래 왼쪽 figure 참고). 그리고, 이전에 QDTrack에 대해 포스팅해놓은 것이 있으니 관심있다면 한번 읽어보시라.. (링크).
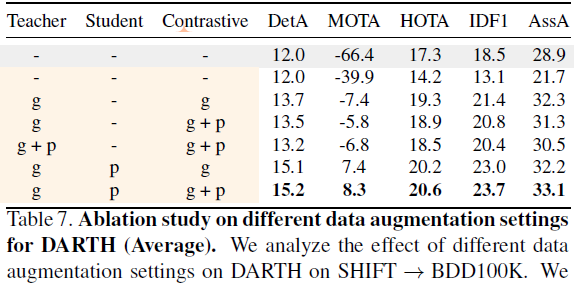
View definition. 위 figure를 보면 input image에 여러 transformation ϕ를 적용하여 여러 views를 만드는 것을 확인할 수 있다. 기본적으로 Contrastive learning을 기반으로 하다보니, 여러 views로부터 positive/negative pairs를 추출하는 것이 중요하다. Teacher view는 GT 같은 기준점이 되어하다보니 ϕT는 weak augmentation (geometric transformatation) 을 사용하였고, student view의 ϕS는 photometric transformation, contrastive view의 ϕS는 geometric + Photometric transformatation을 사용했다고 한다.
Method - Patch Contrastive Learning (PCL)
QDTrack의 contrastive learning 과 매~~~우 비슷하다 😣. 다른 점이 있다면, QDTrack 에서는 두 instance 사이 IoU를 기준으로 positive/negative pairs를 구했지만 DARTH에서는 teacher view와의 consistency를 기반으로 positive/negative pair를 정한다. student view의 detection (^DS), contrastive view의 detection (^DC), teacher view의 detection (ˆD) 를 가정해보자. ^DS이 ˆD에 매칭되었다고 했을때 (IoU > 0.7), ^DC이 ˆD에 매칭되면 positive pair, 그렇지 않으면 negative pair라고 부른다.
(구체적으로 IoU < 0.3 일때 negative pair로 분류됨)
이후, QDTrack과 동일한 loss를 사용하여 contrastive learning을 진행한다 (stability를 위해 loss를 변경하는 것도 동일하고, auxiliary loss를 줘서 magnitude와 angle을 supervise 하는 것도 동일함). 이 논문의 표현을 빌리자면 Contrastive loss를 minimize함으로써 target domain에 appearance representation을 adapt한다고 한다.
Method - Detection Consistency (DC)
Motivation : strong augmentation (photometric transformation)을 통해 변형된 pair 와의 similarity를 계속 강조시키다보면 원래 domain의 정보를 잃어버리지 않을까? 👉 weak augmentation (geometric transformation) 만 수행한 instance랑 consistency를 줄이는 loss를 줘야겠다! 👍 RPN/RoI features 두개에 대해 loss룰 준다 (위 Faster-RCNN 구조 참고)
RPN Consistency. RPN은 (1) instance가 있을지 없을지에 대한 binary prediction s, (2) bounding box에 대한 location 예측 r을 수행한다. DARTH는 이 두 정보에 대한 consistency (L2-norm) 를 minimize한다.
RoI Consistency. 여기서 RoI는 최종적인 (1) per-class prediction ˜p과 (2) instance localization t 을 의미한다.
Total loss. 앞서 나온 모든 loss들을 한꺼번에 고려하여 end-to-end fashion으로 통째로 학습시킨다.
Experimental Setting
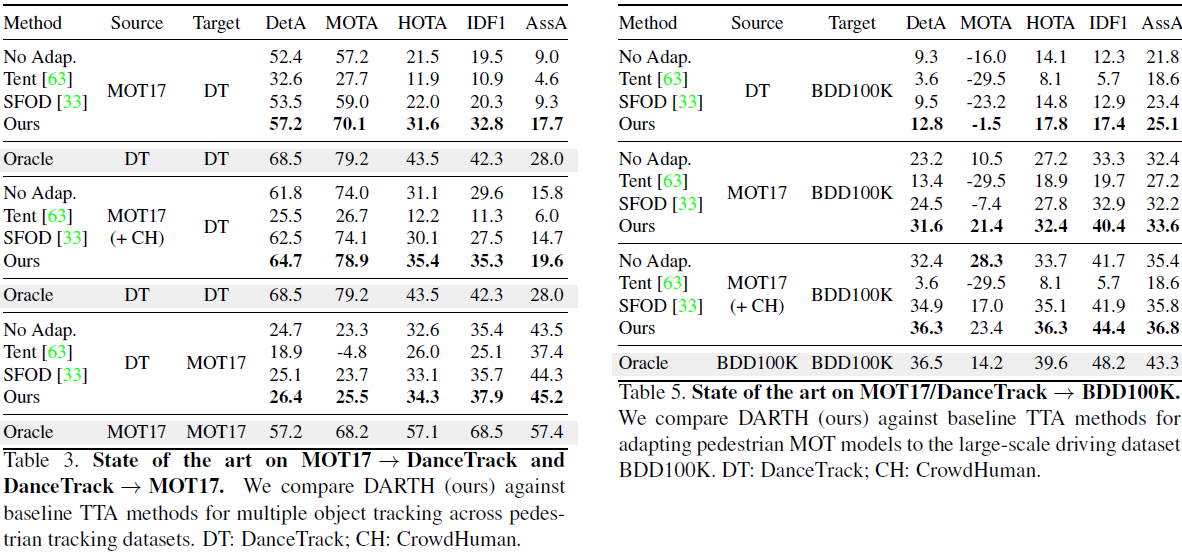
기본적으로 DARTH는 offline TTA problem을 푼다 (이미 target domain data가 다 있다고 가정하는건데 online이 아니라 좀 아쉽다 🤔). MOT는 classification 의 PACS 나 OfficeHome 처럼 깔끔하게 class가 일치하는 TTA용 데이터셋이 없다. 그래서 DARTH는 여러 MOT dataset에서 서로 겹치는 category만 훈련/예측하는 방법을 취했다.
세가지 경우의 domain shift를 시뮬레이션했는데 그 종류가 다음과 같다.
(1) sim-to-real : SHIFT → BDD100K
(2) outdoor-to-indoor : MOT17 → DanceTrack, BDD100K → BDD100K
(3) small-to-large : MOT17 → BDD100K, DanceTrack → BDD100K,
네가지 경우의 baseline을 사용했는데 그 종류가 다음과 같다.
(1) No adaptation : source data 에만 가지고 모델을 훈련하고 별도의 adaptation을 하지 않음
(2) Tent : RoI head 에 대해서 entropy를 minimize하도록 batch normalization layer의 parameter를 optimize
(3) SFOD : object detection을 위해 사용된 TTA method
(4) Oracle : Target domain에서 label 까지 사용해서 훈련한 모델
Experimental Result