이 논문은 CVPR'23에 publish된 논문으로 2023.11.30 기준 4회의 citation을 보유하고 있다.
논문은 https://openaccess.thecvf.com/content/CVPR2023/html/Lin_Video_Test-Time_Adaptation_for_Action_Recognition_CVPR_2023_paper.html 에서 찾아볼 수 있고, 코드는 https://github.com/wlin-at/ViTTA 에서 찾아볼 수 있다.
Introduction
이 논문은 action recognition (video) 에다가 (자칭) Test-time adaptation (TTA) 을 최초로 접목시킨 논문이다. 기존에 image classification domain에서 TTA를 다룬 논문은 여럿 있었지만, video data의 특성 (motion blur, illumination chage) 때문에 image에서나 쓰던 TTA를 그대로 접목시키는건 한계가 있다고 한다 🤔. 이 논문은 video의 특성을 야무지게 고려하여 TTA for online action recognition (ViTTA) 을 제안하였다.
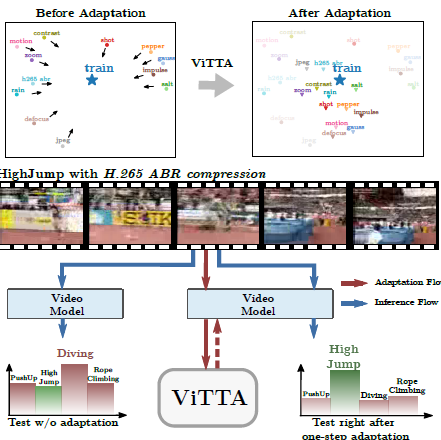
이 논문에서 집중적으로 제안하는 기술은 feature alignment 이다. 기존 TTA 에서 많이들 하던 것처럼 BN layer의 statistics을 test-domain의 것으로 adapt하는 기술인데, 어째 보던 기술만 또 보고 또 보고 또 보는 것 같다 (새로운거 없나? 🤦♂️)
뭐 그래도 Image classification에서 쓰던 기술을 그대로 video에 적용하기는 힘들다고 하는데, 그 이유는 비디오에서 (특히 online setting)에서 large test batches를 확보하기 어렵기 때문이다. 이 논문은 temporal augmentation (이웃 frame 까지 함께 고려해서 feature 계산) 을 사용했는데 이를 통해서
(1) 늘어난 batch size로부터 정확한 statistics를 계산할 수 있고,
(2) 여러 frames 들 사이에 consistency loss를 활용할 수 있다고한다.
제안한 알고리즘은 single distribution shift, random distribution shift (계속 바뀜) 세팅들 모두 좋은 성능을 보였다고 한다.
Method - Video Test-Time Adapatation (ViTTA)
Feature distribution alignment. 우선 이 method는 training dataset의 BN statistics (mean $\mu$, variance $\sigma^2$를 미리 가지고 있다고 가정한다. 이 statistics를 가지고 아래 그림과 같이 test-domain의 feature를 다시 train-domain으로 adapt시키는 알고리즘이다. (정말 간단하다! 😥) 이때 AdaIN 처럼 feature transfer 같은걸 생각할 수도 있긴 하겠지만, 이 논문에서는 train - test domain 의 BN statistics 사이의 L1 norm을 감소시키는 Loss를 사용했다.
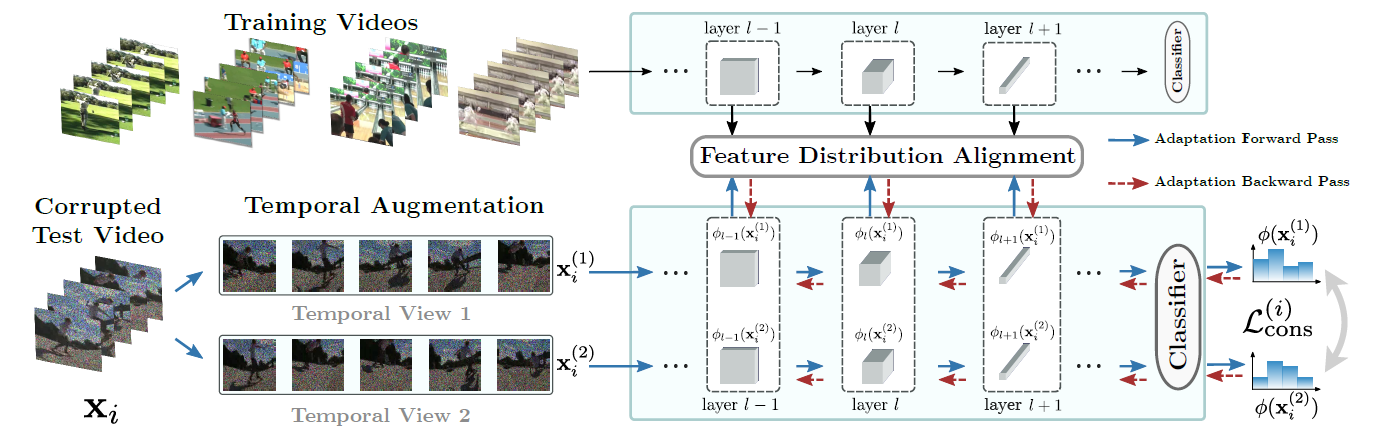
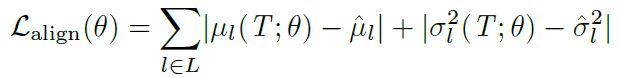
여기서 online setup이기 때문에 batch size가 작다는 문제가 발생하는데, 이 논문은 다음과 같은 방법을 제안한다.
(1) exponential moving averages : 과거 frames 의 features 들의 EMA 로 batch statistics를 update한다.
여러 frame의 statistics를 평균내기 때문에 좀더 신뢰할 수 있는 estimation을 할 수 있다.
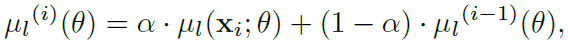
(2) temporal alignment : 각각 timestep에서 batch statistics를 계산할때 같은 video sequence에서 다른 frame의 이미지를 싹싹 긁어모아서 batch를 구성하고 statistics를 계산한다.
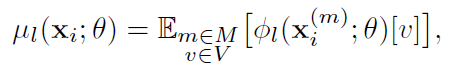
Temporal consistency. feature alignment 뿐만 아니라, ViTTA는 여러 temporal augmentation 사이 consistency를 minimize하는 loss를 제안한다. 여타 다른 TTA works에서 self-supervised auxiliary task를 선보였던 것처럼 test domain의 representation learning에 도움을 줘 generalization capability를 향상시켜줄 것이다. (신박한거 없나? 🤦♂️)
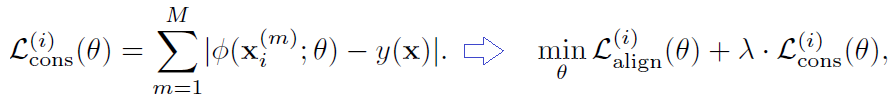
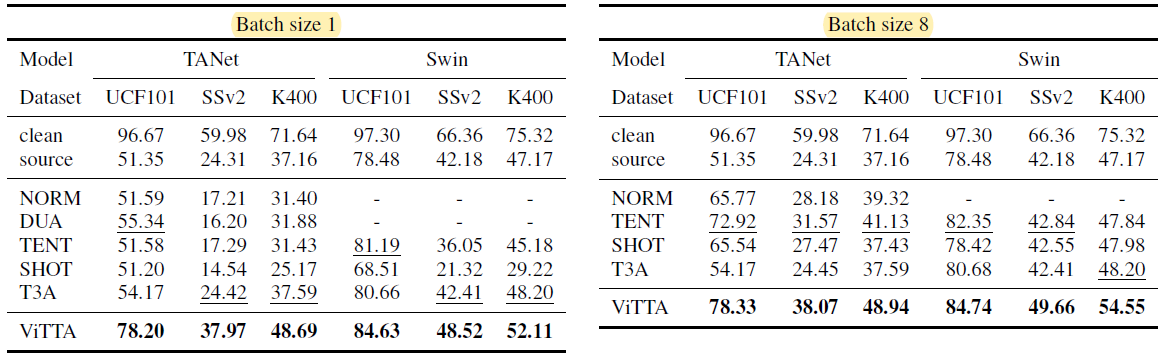
Experimental Results
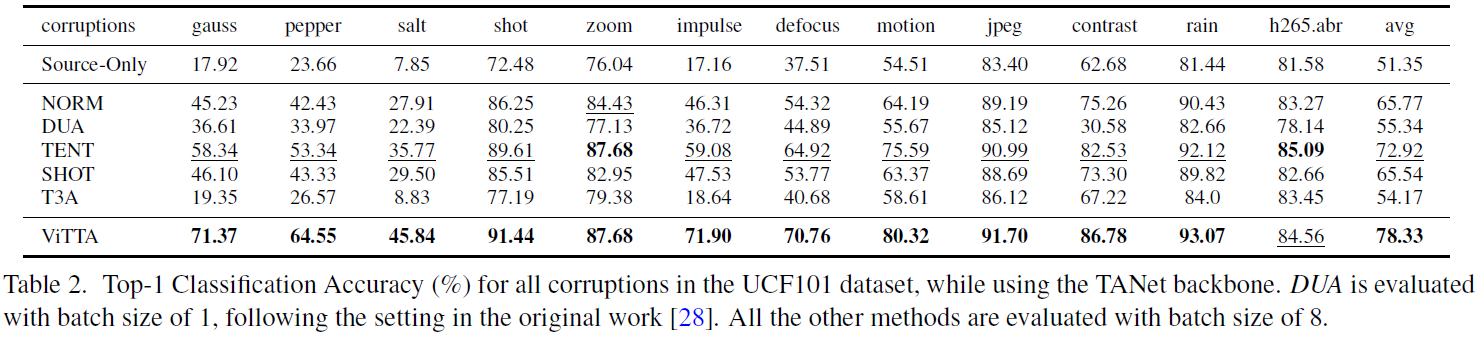
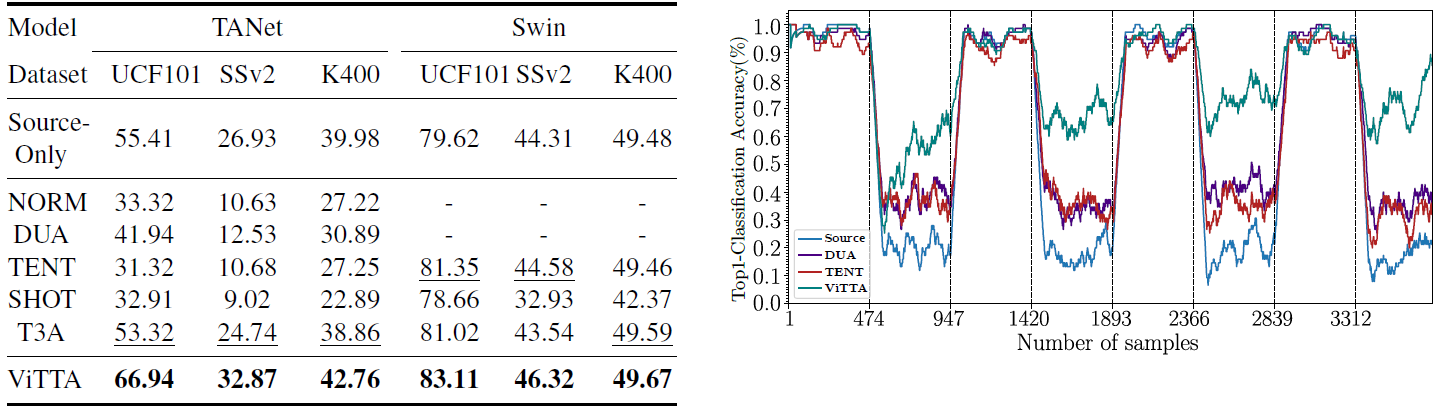
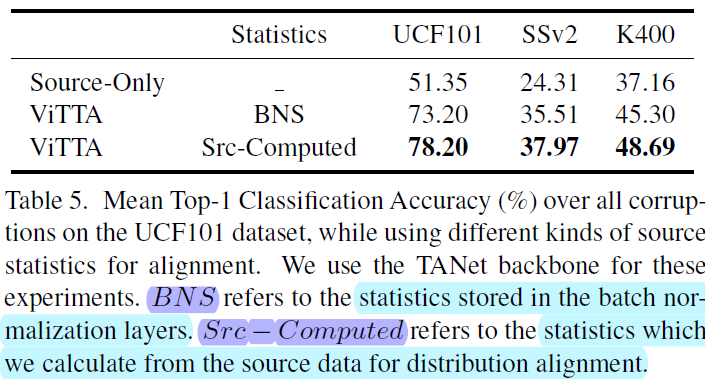
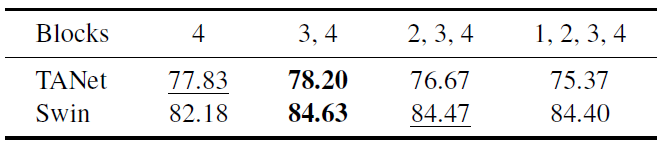
이상 끝!!



