◻ 이 논문은 Arxiv'22에 upload된 논문으로 2024.04.09 기준 3회의 citation을 보유하고 있다.
◻ 이 논문은 budget-aware few-shot learning이라는 새로운 문제를 제안한다. 기존의 few-shot learning은 random 하게 선택된 소수의 support samples이 주어지고, 여기에 모델을 빠르게 적응시켜야했다. budget-aware few-shot learning은 많은 unlabeled data 중에서 active하게 소수의 annotate가 필요한 support samples 후보를 직접 선택한다.
◻ 이 논문은 graph convolutional network(GCN) 기반의 selection policy와 few-shot classifier를 동시에 meta-learn하는 방법을 제안했다. 👉 GCN의 message passing으로 가공된 feature를 informativeness 계산을 위해 사용한다고 한다.
◻ 이 논문은/https://arxiv.org/pdf/2201.02304.pdf 에서 찾아볼 수 있다. 😉
Introduction

◻ 대체적으로 abstract에서 했던말을 반복한다.
◻ 이 setting에서 data를 어떻게 annotate하고 모델을 어떻게 학습한다는 내용이 있는데 설명이 부실하다.
◽ problem setting 까지 봐야 제대로 이해가될 듯 하다.
Problem Formulation

◻ 위 이미지에 모든게 설명되어 있다.
◽ few-shot classification처럼 매번 새로운 task에 대해 adaptation & evaluation을 수행한다.
◽ Evaluation (E)는 few-shot learning의 query set에 대응된다.
◽ informativeness estimator (for active selection)는 meta-train stage에 학습된다.
◽ 각 episode에 소수의 labeled set이 주어지고, informative unlabled sample이 선택된다.
◽ 여기서 선택된 unlabeled sample은 labeld set에 추가된다.
◽ informative sample의 selection 및 추가는 한 episode안에서 여러번 이루어진다.
Methodology
Few-shot classification network.
◻ Prototypical network같은 existing few-shot classifier를 사용한다.
Data Selection Policy Network.
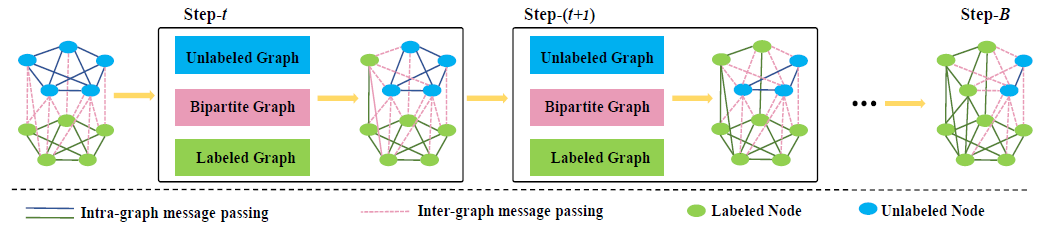
◻ labeled set, unlabeled set에 대해 각각 graph가 존재하고, 그 사이를 연결하는 bipartite graph가 존재한다.
◽ labeled & unlabeled data point가 graph의 node에 대응된다.
◽ labeled & unlabeled graph같은 경우, 각 set의 data에 대해서만 edge가 연결되어 있다.
◽ 모든 node 사이 dense connection (bipartite graph)가 존재한다.
◽ Bipartite graph의 경우 같은 set끼리는 연결이 없고, 서로 다른 set의 sample 사이에만 edge가 연결되어 있다.
◽ 이후 iterative message passing을 통해 labeled 👉 unlabeled data 방향으로 context 정보가 이동한다.
Message Passing Mechanism.
◻ 다음 두가지의 message passing (node feature update) 이 존재한다.
(1) intra-graph message passing

◻ labeeld set의 global context를 encode하기 위해 수행한다.
◽ Summation 대상을 살펴보면,, labeled samples만 고려하는 것을 알 수 있다.
◻ $\phi$는 두 node 사이의 affinity score이다.
◻ $h_i$는 node i의 feature이고, $W^l$은 labeled set의 weight matrix라는 뜻이다.
(2) inter-graph message passing

◻ unlabeled data set의 label context를 capture하기 위해 수행한다고 한다. (이게 무슨말이지? 🤔)
◽ Summation 대상을 살펴보면,, 다른 set의 samples만 고려하는 것을 알 수 있다.
Representation for Informativeness.
◻ labeled, unlabeled data 각각에 대해 다음 형태의 graph representation을 사용한다.

◻ 이 정보는 이후 informativeness를 계산하는데 사용된다.
◽ 여러 layer (# of message passing steps)의 represenation 정보를 concat해서 사용한다.
Meta-Learning Strategy.
◻ meta-loss은 아래와 같다.


◻ 결국 샘플들간 informativeness score 사이 ranking을 정하는 loss인데,, hinge loss를 사용했다.
👉 select시 accuracy gain이 큰 샘플에 대해 더 높은 informativeness score를 부여하도록 학습한다.
👉 support set 사이즈가 작아 모든 sample pair에 대한 비교를 수행하는게 가능하다고 한다..
◻ 전체 학습 알고리즘은 아래와 같다.


