당장 MOT에 대해 아는건 없고, 서베이를 하나 읽긴해야할 것 같아서 2022년에 나온 서베이 논문을 읽어보았다. 😃
(논문 링크 : https://browse.arxiv.org/pdf/2209.04796.pdf)
0. Abstract
MOT는 occlusion, similar appearance, small object detection difficulty, ID switching 등을 해결해야하는 고난이도 computer vision task이다. 이 문제를 해결하기 위해 transformer의 attentioin mechanism, GCN을 사용한 tracklet 사이의 interrelation 측정, siamese network을 사용한 appearance similarity 측정, CNN 을 사용한 IoU matching, LSTM을 통한 motion prediction 등 다양한 방법론들이 제안되었다. 이 리뷰논문은 100개가 넘는 MOT 논문 (2020~2022 사이 거의 모든 논문이라고 한다!) 들을 여러 direction에 따라 예쁘게 정리했다고 한다. 😁👍
1. MOT's main challenges
A. Occlusion
Occlusion은 object of interset가 다른 object에 의해서 가려지는 현상을 말한다. 대부분의 MOT task는 sensor data를 사용하지 않기 때문에 occlusion은 꽤나 어려운 문제라고한다. 예전에는 object를 bounding box를 사용해서 locate하는게 유행이었다고 하는데, 이 방식은 crowded scene에서 occlusion에 불리하기 때문에 segmentation과 융합한 방법들이 제안되었다고 한다. 그 이외에 graph information을 사용해서 global attribute을 찾아 occlusion을 해결하는 경우도 있다고 한다.
B. Challenges for Lightweight Architecture
MOT가 real-time applications에 필요한것과 반대로, 대부분의 MOT architecture는 굉장히 무겁다고 한다.
C. Some Common Challenges
위의 문제점 이외에도 inaccurate object detection, lighting, motion blurring, association, initalization and termination of tracks, ID switching, small-sized object, 등등... MOT 에서 해결해야할 문제들이 한가득있다.🤔
2. MOT approaches

A. Transformer
원래 Transformer는 NLP를 위해 개발된 모델이지만, transformer의 sequential information을 처리할 수 있는 능력과, 뛰어난 contextual memorization 능력 때문에 MOT에도 많이 사용된다 😏
(보통 previous information을 사용해서 object의 다음 위치를 예측하는데에 많이 사용한다고 한다).

TransTrack, TrackFormer : transformer를 사용해서 object query, track query 각각의 bounding box를 예측하고, IoU matching을 통해 association을 수행함.
PatchTrack : 이미지 patches들을 먼저 detect하고, 확률적인 concept을 사용해서 track의 위치를 예측함.
Segdq : Dynamic Object Query (DOQ)를 도입해서 detection을 더 flexible하게 함. query-based tracking을 segmentation에도 사용하여 multi-task learning을 수행함.
Siamese transformer pyramid network, Efficient visual tracking with exemplar transformers : transformer + MOT의 computation cost를 낮추는데 집중한 논문
Motr : object detection transformer 인 DETR에다가 Query Interaction Module을 추가해서 tracking 기능을 추가
Vitt : transformer의 encoder를 활용하여 bounding box classification, regression, embedding을 사용. Lightweigt architecture가 특징이라고 함.

B. Graph Model
이 approach는 Graph Convolution Network (GCN) 을 사용하고, 이 GCN에서는 연속적인 frame의 objects들이 node로, 그 node 사이 link가 edge로 모델링된다. 기존의 Hungarian algorithm으로 association 문제를 풀던것을 GCN으로 해결한다.

MOT neural solver : Message Passing Network (MPN)을 사용해서 그래프로부터 deep feature를 추출함
GNMOT : Appearance graph network와 motion graph network을 사용하여 각각으로부터 similarity를 측정
LPC_MOT : GNMOT처럼 두개의 GCN을 사용하는데, 하나는 proposal을 generate하고, 다른 하나는 proposal을 score
GMTracker : association problem과 assignment problem을 해결. assignment problem을 풀기 위해 quadratic programming layer를 사용하여 robust feature를 배움

C. Detection and Target Association
일반적인 object detection model로 bounding box들을 detect하고 target association을 뒤이어 진행하는 general한 방법들.
CCC : top-down approach에서는 bounding box를 결정하고, bottom-up approach에서는 point trajectory를 찾음.
Track-RCNN : 3D CNN을 사용하여 detection, tracking, segmentation을 동시 수행
Fairmot : object detection, re-identification 을 각각 수행하는 두개의 branch를 제안
DRT : semi-supervised learning을 통해 object를 찾는데 도움이 되는 heatmap을 생성하는 방법을 학습
CorrTracker : Correlation network를 사용하여 associations들 사이에 information을 propagate함
QDTrack : Quasi Dense Tracking Model을 제안하고 similarity learning을 수행
D2LA : Fairmot를 확장한 연구이며, attention module의 복잡도를 줄이고 accuracy와 complexity 사이의 trade-off을 연구.
TraDeS : Cost Volume based Association (CVA) module과 Motion-guided Feature Warper (MFW) 를 제안하여 obejct localization 정보를 추출하고 이 정보 각각을 transmit from frame to frame.
Det : Depth-enhanced tracker (Det)를 제안하여 tracking-by-detection 전략을 발전시킴
JLA : Fairmot을 사용하여 bounding box를 예측하고, Joint Learning Architecture (JLA)을 제안함
JDI : NMS를 통해 redundant object을 detector에서 제거함. feature을 비교하여 trajctory location을 re-detect하고, IoU을 사용하여 bounding box를 re-identify하는 joint re-detection and re-identification tracker (JDI) 제안

D. Attention Module
Occlusion 된 object를 re-identify 할때 attention을 사용할 수 있다. 이 리뷰 논문에 따르면, target object의 background를 nullify (무효화) 하면 object의 feature만 오래오래 기억할 수 있다고 한다 (심지어 occlusion이 일어난 뒤까지도!) 🤔
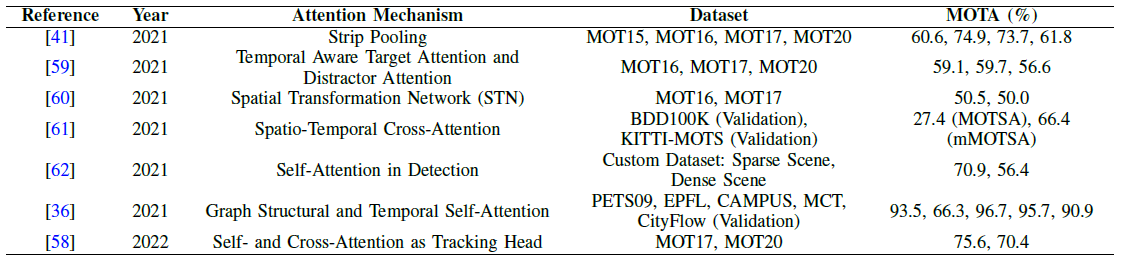
D2LA : strip attention module을 사용하셔 occluded 되었던 object를 다시 re-identify함. module이 pooling layer (e.g., max pool / mean pool) 로만 구성된 원시적인 형태라고 한다.
TADAM : object ocation information과 data association information 를 전부 사용하기 위해 두개의 attention modules을 사용한다고 한다. 또한, memory aggregation을 적용하여 strong attention을 가능케했다고함.
STN : Spatial Transformation Network (STN)을 사용하여 appearnace model이 foreground에만 집중하도록 함
PCAM : Prototypical Cross-Attention Module (PCAM)을 제안하여 과거 frames에서 관련있는 정보를 추출함. Background와 Foreground 사이 contrasting feature는 Prototypical Cross-Attention Network (PCAM) 을 통해 이후 frames들로 전달
Dyglip : Self-attention module에 dynamic grpah를 적용하여 camera의 internal/external information을 결합
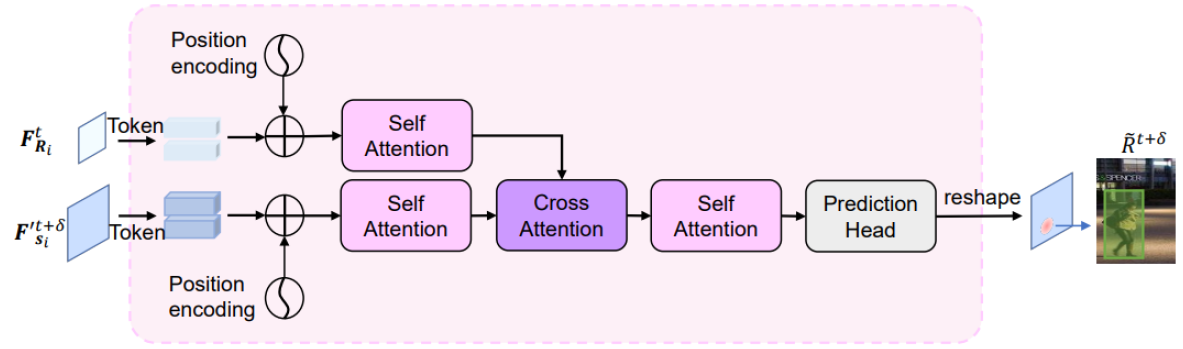
DsrrTracker : self-attention과 cross-attention을 전부 사용하는 형태 (위의 그림임, Transformer랑은 다름). Self-attention module은 foreground가 강조된 robust feature를 추출하고, cross-attention module은 추출된 정보를 활용하여 data association을 수행한다.
E. Motion Model
이 리뷰에서 정의한 motion이란 두개의 frame (꼭 연속될 필요는 없다) 사이 object의 위치 차이이다.
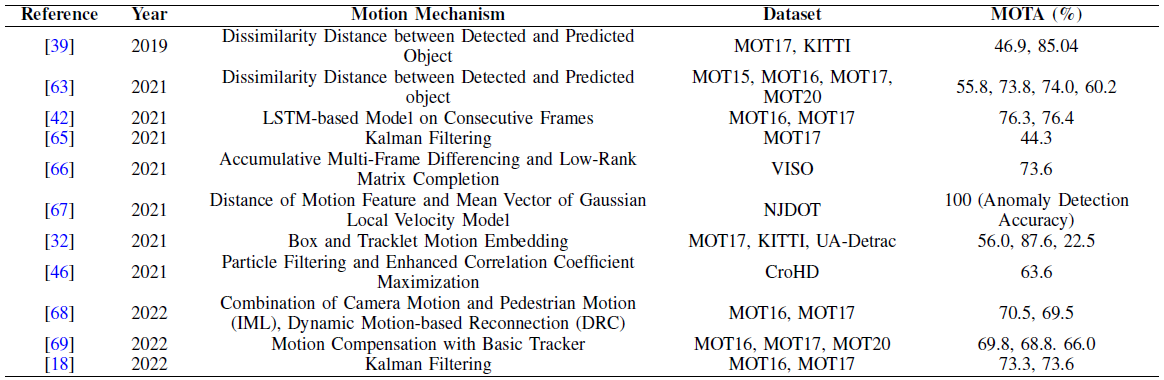
MASS, JLA [39,63] : 실제 위치와 예측된 위치 사이의 차이 (motion)을 측정해서 dissimilarity cost로 사용함.
[64] : object가 위치할 수 없는 공간을 eliminate 하는 것으로 data association을 최적화함
VISO [66] : 연속적인 위성 사진 frames 사이의 distance를 측정. 이때 Accumlative Multi-Frame Differencing (AMFD)와 Low-Rank Matrix Completion (LMRC)를 사용했다고 함. 이후 Motion Model Baseline (MMB)를 사용해 false alarm의 수를 줄였다고 함
[67] : motion 정보를 사용하는 GLV 모델을 통해 foreground 를 식별
[32] : Local-Global Motion (LGM) tracker 를 사용하여 motion 사이 연관성을 측정하고 이를 association에 사용
[46] : motion model을 사용하여 object의 motion을 예측함. Integrated Motion Loicalization (IML), Dynamic Reconnection Context (DRC), 3D Integral Image (3DII) 라는 3개의 모듈을 사용했다고 한다.
[68] : Motion-Aware Tracker (MAT) 을 통해 motion prediction과 association을 동시에 해결
[69] : Compensation tracker (CT)를 사용해 lost objects를 다시 찾아냄 🤔🤔
F. Siamese Network
여기서는 Siamese network을 사용하여 두 frame 과의 similarity를 활용하는 방법론들을 다룬다. Siamese Network는 parameter가 동일한 twin networks구조를 가지고 있으며 input의 similarity를 계산하는 방법을 배운다.
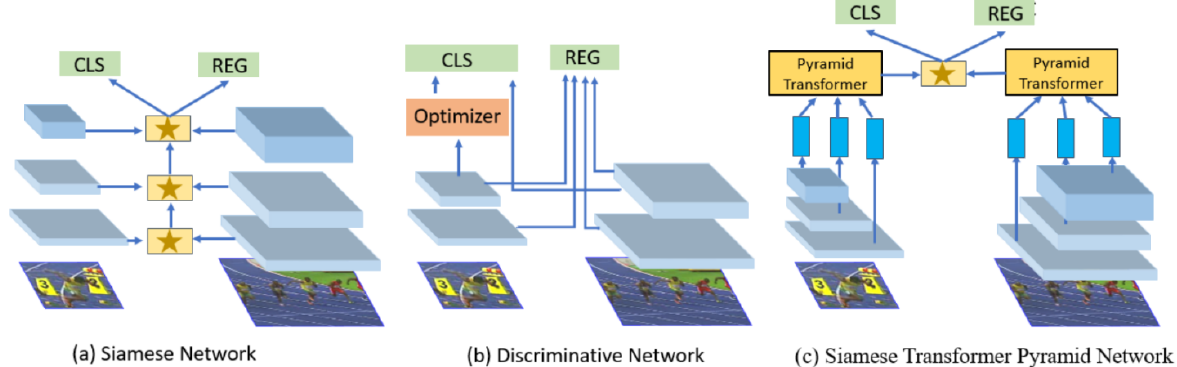
[22] : Siamese Transformer Pyramid Network (STPN)을 제안. Target object, 그리고 그 주위의 이미지가 추가된 augmented object을 STPN에 통과시킨뒤 결합시켜서 더 강인한 target-specific appearance representation을 생성
[70] : Faster-RCNN에 Siamese network tracking framework을 추가시켜서 더 빠르고 가벼운 MOT를 구현
[31] : Siamese Bi-directional GRU (SiaBiGRU)를 제안. Corrupted tracklets를 제거하는 후처리를 제안.
[71] : Siamese RPN을 제안. 또한, adaptive threshold determination method를 제안하여 data association module과 Siamese network의 안정성을 향상시켰다고 함
[21] : Siamese network의 CNN을 exemplar transformer layer로 교체하여 효율성을 증가시킴

G. Tracklet Association
연속적인 frames들 사이에서 object를 짧게 짧게 추적하여 연결한 trajectory 조각을 tracklet이라고 한다. 아예 처음부터 전체 long trajectory를 구성하는 것보다, 일단 여러개의 짧은 tracklet을 만들어놓고 이걸 연결해서 trajectory를 완성한단다.
TPM [72] : 일단 짧은 tracklet들을 만들고나서, hyperplane에 할당해서 (?) larget trajectory를 완성
[73] : 3D geometric algorithm을 사용해서 tracklet을 만들고, 여러 카메라로부터 얻은 spatial / temporal information을 사용해서 global association을 수행
PPN [31] : Position Projection Network (PPN)을 사용해서 local trajectory를 global trajectory로 transfer. Tracklet들을 input으로 motion prediction에 활용
[75] : Trajectory-centor Memory Bank (TMB)에 tracklet을 저장하고 cost를 계산하는데 사용. Multi-view Trajectory Contrastive Learning (MTCL)을 통해 이 학습을 진행. Learnable View Sampling (LVS) 을 사용하여 trajectory를 global context로 해석하고 long trajectory를 완성
TBooster [76] : Splitter와 Connector를 사용하여 association의 error를 줄임. Splitter는 ID switching이 일어나는 점을 분기로 tracklets을 나누고, Connector는 이를 잘 연결해서 association 성능을 개선

3. MOT Benchmarks
기본적으로 MOT dataset 은 video sequences로 이루어져있고, 각각의 sequence 안에는 unique ID로 식별되는 여러개의 object들이 등장한다. MOT에는 여러종류의 benchmark dataset이 존재하는데, 그중 가장 대중적인 것은 MOT challenge 시리즈이다. MOT15 데이터셋은 Venice, KITTI, ADL-Rundle, ETH-Pescross, ETH-Sunnyday, PETs, TUD-Crossing 을 포함한다. 이 데이터셋은 unconstrained environment (static/moving camera) 에서 촬영되었다고 한다.
MOT16, MOT17은 더 좋은 ground truth를 갖도록 업그레이드된 버전이고,
MOT20은 pedestrian detection challenge 라고한다.
MOT 시리즈말고도, PETS, STEPS, DenseTrack, TAO, Head Tracking 21, STEP 등의 데이터셋이 존재한다.
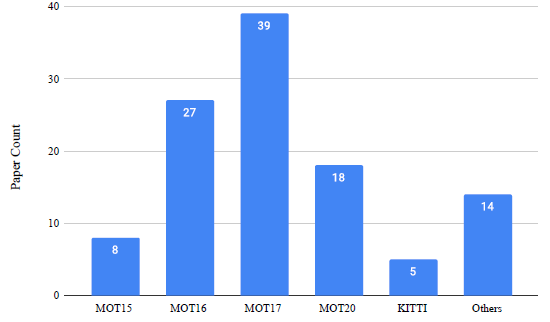
4. MOT Metrics
굉~~장히 많은 metric들이 있다. 왠만하면 전부 포스팅해려고 했는데, 너무 많고 내용도 복잡해서 이름만 언급하기로...
MOTP, MOTA || IDF1 || Track-mAP || HOTA || LocA || AssA || DetA || DetRe || DetPr || AssRe || AssPr || MOTSA AMOTA
5. Applications
MOT의 활용방안은 몇가지 field로 국한되지 않지만, 몇가지 유명한 application을 대보자면 다음과 같다.
Autonomous driving || Pedestrian tracking || Vehicle Surveillance || Sports Player Tracking || Wild life tracking
6. Future Directions
이미 활발하게 다양한 분야가 연구되었지만, 그럼에도 몇몇 잠재적인 개선 방향을 고려해보자면 다음과 같다.
1) multiple camera 로부터 얻은 다양한 scene을 fuse해서 MOT 성능을 향상하는 방향
2) class-basecd tracking system : 특정 클래스만 추적하거나, 특정 클래스는 추적하지 않거나하는 방향
3) 3D video 를 사용한 MOT : occlusion에 강인하다고 한다
4) lightweight architecture : real-time application 을 위해 매우 중요함
5) inference time reduction : 위와 같은 이유로 중요함
6) Quantum computing : N-P hard association problem을 푸는데 유용하게 사용될 수 있다고 함
* 특히 4) 5) 은 최근 무거운 transformer-based architecture를 많이 차용하는 MOT 트랜드 (transformerd의 contextual information memorization 능력때문에 assignment problem을 풀기에 좋다) 에 따라 더 의미가 있다고 한다.
'Object Tracking 공부' 카테고리의 다른 글
| QDTrack: Quasi-Dense Similarity Learning for Multiple Object Tracking 논문 공부 (0) | 2023.10.23 |
|---|---|
| Learning a Neural Solver for Multiple Object Tracking 논문 공부 (0) | 2023.10.16 |
| TrackFormer: Multi-Object Tracking with Transformers 논문 공부 (0) | 2023.10.13 |
| DeepSORT : SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC 논문 공부 (0) | 2023.10.07 |
| Object Tracking 개념 공부 (1) | 2023.10.06 |


