1. Introduction
MOT의 목표는 video sequence안에서 objecrt의 trajectory들을 찾아내는 것이다. (이 논문 나올때 기준의) 대부분의 MOT 방법론들은 tracking-by-detection 또는 tracking-by-regression의 형태를 취하고 있었다.
- Tracking-by-detection : 일단 object들을 detect하고 나서, data association을 추가로 수행하는 형태
- Tracking-by-regression : data association을 수행하지 않고, regression module을 통해 motion prediction을 수행
하지만 기존의 방법들은 추가적인 nerual net module이 필요하거나, 계산 복잡도가 높은 추가 최적화 계산이 필요했다.
이 논문에서는 tracking-by-attention이라는 새로운 패러다임을 제시하는데, transformer의 encoder-decoder 구조를 사용해서 detetction과 tracking을 동시에 수행한다 (i.e., bounding box를 예측할때 ID도 함께 예측하는 것). 이를 통해 기존의 graph optimization, modeling of motion/appearance, track matching 등의 연산으로부터 자유로울 수 있다고 한다.
contribution을 요약하자면 다음과 같다.
- 새롭게 tracking-by-attention 패러다임을 제안하고, detection과 assocation을 동시에 수행
- Autoregressive track queries (Transforemr 구조)를 사용하여 object의 위치, ID, class 를 동시에 예측하는 법 제안
- MOT17, MOT20 에서 SoTA 성능 달성
2. Methodology
중요한 개념 : encoder-decoder Transformer 구조, tracking-by-attention 패러다임, track/object queries의 콘셉
TrackFormer는 다음 4 steps를 거쳐 object detection과 ID association을 수행한다.
- Frame-level feature extraction with a common CNN backbone (e.g., ResNet-50)
- Encoding of frame features with self-attention in a Transformer encoder
- 한 scene (frame) 안에 있는 object 간의 attention을 통해 joint reasoning을 가능하게 한다. - Decoding of queries with self- and encoder-decoder attention in a Transformer decoder
- 여러 frame의 encoded feature에 globally 접근함을 통해, motion/ID 예측에 도움을 준다. - Mapping of queries to box and class predictions using multiplayer perceptrons (MLP)
TrackFormer의 동작을 이해하려면 object query와, track query의 개념을 이해해야한다.
- Object queries : static (but learned) query, 새로운 track을 발견하기 위해 사용된다.
- Track queries : autoregressive query, 기존의 track을 갱신하거나 삭제하기 위해 사용된다.
TrackFormer는 위 두개의 queries를 동시에 사용하는 것으로 detection과 tracking을 unified way로 수행한다.
(모델 마지막에 달린 MLP가 localization을 수행하기는하나, 실질적인 track assoication은 transformer가 담당하는 셈이다)
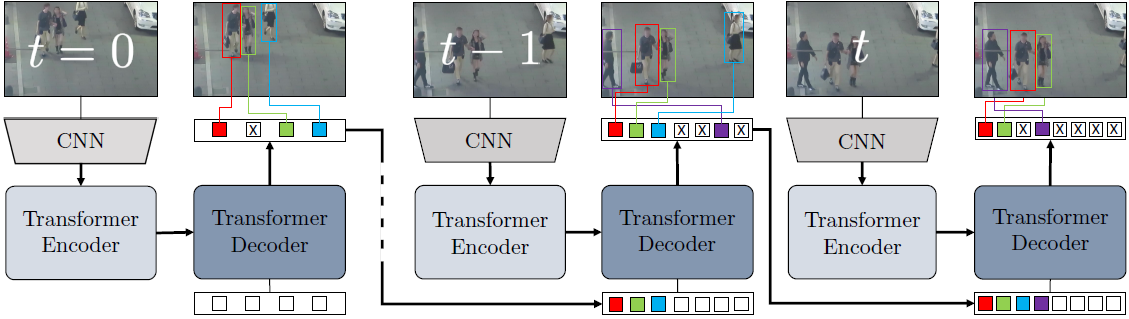
[1] Track initialization : 새로운 track은 object query에 의해 찾아진다. 고정된 개수의 object query (위 그림에선 4개) 가 decoder를 통과하여 new objects를 찾아낸다. Transformer의 self-attention 을 통해서 중복된 detection을 피할 수 있다.
[2] Track queries : track queries는 frame-to-frame track generation을 담당한다. 구체적으로, track query는 비디오 시퀀스를 통과하면서 object의 identity information을 autoregressive manner로 전달한다.
[3] Track query re-identification : occlusion등에 대응하기 위한 테크닉이다. TrackFormer엔 $T_{track-reid}$ 의 길이의 frame동안 track queries를 보관하고 있다가 classification score가 충분히 다시 높아지면 trajectory를 다시 갱신한다. 별도의 re-identification training 없이 한번에 수행할 수 있는 점이 TrackFormer의 강ㅈ엄이라고 한다.
3. TrackFormer training
기본적으로 object detection과 비슷하게 classification loss로는 CE loss, localization loss를 L1 distance와 IoU loss를 사용한다. 하지만 단순 detection과는 다른것이, tracking에서는 각각의 object들이 Track ID를 가지고 있다보니, loss를 계산하기 전에 Bipartite matching을 통해 detection (prediction)과 ground truth를 연결해주어야한다. Frame t에서 나타나는 track identity의 set을 $K_t$ 라고하자 (track query의 ID와 동일). 이때 matching에 있어서, 세가지 경우의 매칭이 존재한다.

[1] 이전 frame의 ID과 현재 frame에도 나타난 경우 : 이 경우는 그냥 ID가 동일한 GT에 간단히 매칭하면 된다.
[2] 이전 frame의 ID가 현재엔 사라진 경우 (위 그림에서 하얀 x 네모 상자에 해당) : background로 매핑한다.
[3] 새로운 ID가 나타난 경우 : 가장 유사한 GT box에 매칭여기서 매칭에 사용하는 cost function은 아래과 같다. prediction이 비슷하거나 거리상으로 가까운 GT box를 고르게된다.

여기서 알수 있는 재미있는 점은, track ID에 대한 loss라는게 따로 존재하지 않는 다는 것이다. 대신 ID matching을 먼저 선행시킨다음 ID를 잘못 match한 track을 penalize하는 방식으로 학습이 진행된다. 모든 matching을 끝마친 이후, 비로소 계산되는 loss는 아래와 같다. (여기서부턴 그냥 detection loss와 동일하다)
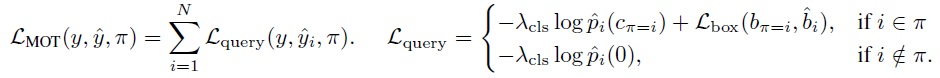
4. Track Augmentation
이 section은 MOT 모델을 학습시키기 위해 필요한 여러 heuristic들을 다룬다. classification 문제에서 flipping, cropping을 하듯이, original 비디오 데이터에서 나타날 수 있는 시나리오들을 augment 시켜서 보다 다양한 문제를 보게 하는 것이다. 별거 아닌것처럼 보여도 성능 향상에 매우 큰 영향을 준다고 한다.
- t-1 에 해당하는 frame sample은 바로 t-1이 아니라 t-N 번째 frame을 뽑는다.
- low frame rates라 camera motion에 대응할 수 있다. - 일정 확률로 false negative를 샘플링한다.
- 잘 맞췄던 prediction을 일부로 false negative로 만든다는 뜻이다. 위의 그림에서 잘 맞춘 colored query를 white query로 바꿔버린다는 뜻. Transformer가 매 scene에서 새로운 object를 더 잘 인식할 수 있도록 도와준다. - False positive를 추가한다.
- 이전 frame에서 background로 classify되었던 query들을 일부로 다음 frame으로 넘긴다. Transformer가 중요하지 않은 object들을 무시할 수 있는 능력을 키우도록 도와준다.



