이 논문은 CVPR'22에 publish된 논문으로 2023.12.08 기준 62회의 citation을 보유하고 있다.
논문은 https://openaccess.thecvf.com/content/CVPR2022/papers/Boudiaf_Parameter-Free_Online_Test-Time_Adaptation_CVPR_2022_paper.pdf 에서 찾아볼 수 있고, 코드는 https://github.com/fiveai/LAME 에서 볼 수 있다.
Introduction
우선 이 논문이 adaptation 이 아니라 correction 에 대한 논문이라는 것을 알고 넘어가자. 여기서 adaptation이란 TTA 동안 model parameter를 update하는 것이고, correction은 model probability를 update하는 것이다 (정확히는 model probability를 대체할 수 있는 latent assignment를 사용한다). 그 외의 실험세팅은 여타 online TTA 와 비슷하다 (no source data, no target label)
이 논문이 지적하기를 기존의 TTA works (e.g., TENT, SHOT) 은 다음의 문제들이 있다.
1) 기존의 TTA works는 low-level corruption이 아닌 고난도 scenario에서 제 성능을 내지 못한다
(심지어 adaptation을 수행하지 않은 baseline 보다 성능이 떨어지는 경우도 있었다고 한다 😮)
2) model parameter를 update해야한다. 이 경우 다음의 문제들이 발생할 수 있다.
👉 오래 걸린다. (특히 online TTA 상황에서 low latency는 치명적이다.)
👉 model을 update하는 과정에서 에러가 쌓여서 (confirmation bias) 모델 자체가 돌아올 수 없는 강을 건너 성능이 감소.
👉 parameter를 update하는 과정에서 여러 hyperparameter에 의존하게 되어 튜닝도 어렵고, generality도 떨어진다.
(여기서 generality가 낮다는 뜻은 한 scenario에서 튜닝한 hyperparamter를 다른 scenario에 적용하기 어렵다는 뜻이다.)
위 문제들을 해결하기 위해 LAME은 model paramter를 update하지 않고 latent assignment를 update한다. 이 이외에도 Laplacian regularization (manifold-smoothness를 가정한 것과 같다고 함) loss term을 추가했다고 한다.
On the Risks of Network Adaptation
백문이 불여일견! 아래 있는 figure를 보자. 일반적인 likelihood shift (ImageNet-C) 환경에서는 adaptation 기반 TTA methods (e.g., TENT, SHOT)이 baseline (no adapted source model) 보다 높은 성능을 보이지만,,, class imbalance가 존재하거나 corruption이 NIID로 발생하는 까다로운 상황에서는 기존의 works이 baseline 보다도 못한 성능을 보인다고 한다.
Network adaptation 방식의 실패 이유로는 1) 일부 target data에 model이 overspecialize 되서 generality를 잃어버리거나 2) sample diversity가 충분하지 않거나 3) 좋은 hyperparameter를 찾기 어렵기 때문이라고 한다.

또 기존의 TTA methods의 더 큰 문제는 내 모델이 망가지고 있는지 알 수가 없다는 것이다 😢. TTA 특성상 target label이 없어서 target accuracy를 알수가 없는데, 기존의 entropy minimization 방식의 method (e.g., TENT, SHOT)에서 entropy가 떨어지는 모습만 봐서는 내 모델이 언제 고장 나고 있는지 알 수 없다는 것이다. 👉 아래 (middle, right) figure 참고
👉 또한 hyperparameter ($\alpha$)에 매우 민감하지만 label이 없어 이를 튜닝할 수 없다는 점도 한 몫 한다.

❔ 이 문제가 발생하는 이유는 무엇일까?
👉 다른 TTA methods 에서도 공통적으로 지적하는 내용이지만, entropy minimization 은 overconfident prediction을 유발시키기 때문에 아래 그림과 같이 decision boundary가 저 멀~리 이동해버릴 수가 있다. 이를 방지하기 위해서 one-hot prediction을 방지하기 위핸 여러 regularization이 등장했고, 대표적으로 SHOT의 feature diversification loss가 있다.

❗ 또한 기존의 TTA method (TENT)는 brittle한 성질을 가진다. 여기서 brittle하다는 것은 한 scenario에서 adaptation을 마친 모델이 다른 scenario에서 좋은 성능을 내지 못한다는 것을 의미한다. 위의 matrix에서 (i,j) 성분은 i scenario 에서 adapt된 모델을 j scenario 에서 test 했을때의 성능인데, TENT의 경우 이곳저곳 새빨간 것이 영 generality가 좋지 않다.
👉 결국 model parameter를 update하는 과정에서 특정 scenario에 overspecialize 되는게 원인인 것이다.

Methodology (LAME)
LAME에서 제안한 main objective function는 다음과 같다. 논문의 설명이 자세하지는 않았지만, $p$ 는 true target label, $z$는 latent assignment (model prediction을 대체할 값), $N$ 은 샘플 개수, $K$는 class 개수.. 인것으로 보인다.
아래 object function은 target data에 대한 likelihood이며, 이를 maximize 하는 방향으로 (MLE) $z$를 optimize 한다. 직관적으로 생각해보면, 높은 $p$에 높은 $z$를 부여하도록 학습이 될 것이다.
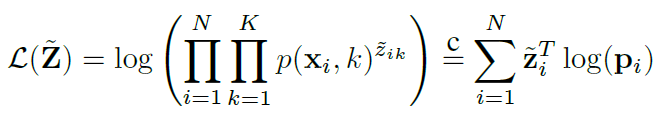
위 학습이 극단적으로 진행되었을때, 높은 $p$ 에 아주 높은 $z$를 one-hot vector 식으로 부여하는 문제가 발생할 수 있는데 이를 방지하기 위해 z에 대한 entropy maximization loss (equal prediction이 되도록 유도) 를 추가로 사용한다고 한다.
최종적인 loss는 아래와 같고, $z$와 $p$ 사이 KL divergence 의 형태로 loss가 구성된다고 한다.

위 loss에 대해 두가지 추가적인 modification이 있는데..
1) target label $p$를 구할 수 없기 때문에 source model prediction $q$를 사용한다.
2) Laplacian regularization 을 적용한다 👉 비슷한 feature를 가진 샘플이 비슷한 $z$를 갖도록 도와준다고 한다.
◼ 아래 $w$는 similarty measure이고 두 샘플 $x_i, x_j$ 사이 feature similarity를 측정한다.
위 두 modification이 반영된 최종 loss는 아래와 같다.

Efficient optimization via a concave-convex procedure
LAME은 model parameter가 아닌 K-vector latent assignment $z$ 만을 학습하기 때문에 별도의 backpropagation없이 convex optimization을 통한 closed form으로 $z$를 update할 수 있다. 위의 loss는 convex (KL divergence) term 과 concave (Laplacian : $W$ 가 positive semi-definite 일때...) term 의 합으로 구성되어 있고, 이 경우 CCCP (Concave-Convex Procedure) 을 사용하여 문제를 풀 수 있다. Concave part를 linear 형태로 1차 근사해서 푸는 방법이라고 하는데 자세한건 Appendix를 참고하면 좋을 것 같다. 어찌저찌 하여 $z$가 수렴할때까지 아래와 같이 update된다고 한다.

Experimental Results
먼저 아래 figure는 hyperparameter search이다. original (MS 에서 배포한 ResNet-50) 을 각각 방식으로 튜닝한 뒤 다른 7개의 test scenario에 적용했을때의 성능을 평균낸 값을 report하는데, LAME이 model architecture나 training procedure에 강인하게 골고루 좋은 성능을 보인다.

다음으로 아래 figure는 LAME 이 기존의 model adaptation 기반 method (TENT) 보다 실행 속도가 훨씬 빠르다는 것을 보여주는데, 이는 역시 모델 parameter가 아니라 latent assignment를 optimize하기 때문에 가능한 것이다.
(backpropogation이 필요 없기 때문이다!)

이상 끝!



