이 논문은 CVPR'23에 publish된 논문으로 2023.12.12 기준 15회의 citation을 보유하고 있다.
Continiual TTA에 사용할 수 있는 memory-efficient method 인데, self-distillation을 추가로 적용하여 catastrophic forgetting에 의한 성능 감소를 완화시켰다. 논문은 https://openaccess.thecvf.com/content/CVPR2023/html/Song_EcoTTA_Memory-Efficient_Continual_Test-Time_Adaptation_via_Self-Distilled_Regularization_CVPR_2023_paper.html에서 찾아볼 수 있고, 코드는 https://github.com/Lily-Le/EcoTTA 에서 확인할 수 있다.
Introduction
먼저, 이 논문은 기존의 TTA methods가 다음과 같은 단점이 있다고 지적한다.
(1) memory complexity가 너무 높다.
👉 TTA 특성상 small edge device에서 동작할 가능성이 높으므로 memory complexity를 낮추는게 중요하다.
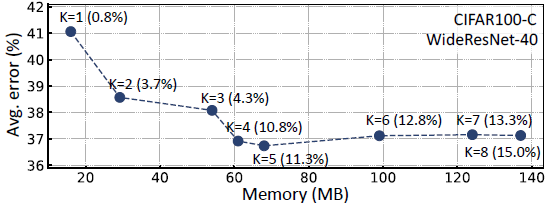
👉 아래 figure에서 TENT나 EATA처럼 일부 BN parameter만 update한다 하더라도, backpropagation을 위해 activation vectors를 저장해야하기 때문에 memory complexity가 낮지 않다.
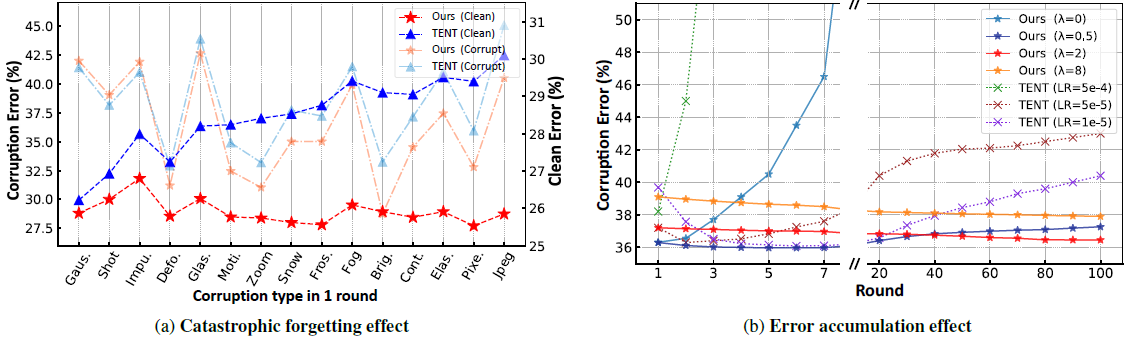
(2) Catastrophic forgetting에 취약하다
👉 이건 특히 continual TTA에 해당되는 내용인데, target domain에 over-adapt되버려서 source 의 정보를 잊게된다.
(3) Error accumulation에 취약하다.
👉 TTA 특성상 unlabeled data를 통해 adaptation을 진행하는데, 이때 confirmation bias에 의한 error accumulation이 발생하여 모델이 맛이 갈 수 있다.

이 논문은 위 문제들을 해결하기 위해 memory-Efficient continual Test-Time Adaptation (EcoTTA)를 제안했다.
알고리즘을 간단하게만 설명하자면,,,,,
(1) main model은 freeze 하고 작은 meta network을 학습시킨다. (위 figure 참고)
👉 기억해야할 activation의 개수가 줄어들어 memory complexity가 낮아진다.
(2) self-distilled regularization loss를 사용한다.
👉 frozen original model과 un-frozen meta network의 output사이 L1 loss를 주어 catastrophic forgetting을 방지한다.
* 상기 meta network을 warm-up 하기 위해서 source dataset 전체가 필요하다고 했는데,,,,, 이점은 좀 아쉽다! 🤔🤔🤔
Method : EcoTTA
이후 EcoTTA 에 대한 설명은 아래 figure를 참고하여 읽으면 좋다.
Memory-efficient Architecture. L,W,f를 각각 loss, parameter, activation이라고 했을때, 아래와 Fig.3과 같이 model parameter를 update하기 위해서는 바로 이전 layer의 activation fi−1이 필요하다 (다른 layer의 activation은 필요없다.)
이 사실로부터 기존 TTA methods의 단점과 memory consumption을 줄이는 해결책을 알 수 있는데...
(1) TENT, EATA 는 update할 BN 수가 많아서 memory complexity가 높다.
(2) 위 BN layers 보다 훨씬 적은 수의 model parameter만 업데이트하면 memory complexity도 낮출 수 있다.
👉 이래서 나온게 EcoTTA의 초소형 meta network이다.
Before Deployment. neural net을 target domain에 deploy하기 전에 EcoTTA는 backbone을 여러 partition으로 쪼개고, 그 사이에 meta network을 끼워넣을 것을 제안했다 (Fig.2 참고). 이 meta network은 source dataset 전체를 다 사용하여 source model과 함께 학습시켜야하는데,,🤔,, 그나마 pre-trained source model을 freeze 시킨 뒤 small number of epochs (less than 10) 을 통해 학습할 수 있다고는 한다... 그래도 Test 때에는 source data를 사용하지 않는다!
After Deployment. 사실상 여기서부터 TTA이다. loss는 간단하게 EATA에서 사용했던 entropy minimization loss를 사용한다. EATA에서 했던것처럼 entropy가 threshold value 보다 낮을때만 model을 update한다고 한다.
이에 더해서 EcoTTA는 self-distilled loss를 추가로 제안했는데, 이를 고려한 최종적인 TTA loss는 다음과 같다.
(k는 meta network의 인덱스인데, 4~5 개정도 존재한다 👉 backbone을 4~5 조각으로 쪼갰다는 뜻)
Self-distsilled Regularization. 별 복잡한 내용은 아니고,, 위 Fig.2 에 잘 나와있듯이, frozen original model과 unfrozen meta network 사이의 차이를 줄이는 loss를 사용한다.
이 loss를 통해 다음과 같은 benefit을 얻을 수 있는데....
(1) Catastrophic forgetting을 방지할 수 있다.
👉 meta network의 output을 source model과 일치시키는 과정에서 source domain knowledge가 보존된다고 한다.
(2) Error accumulation을 방지할 수 있다.
👉 original model의 class discriminability를 사용할 수 있다. (🤔음? (1) 이랑 뭐가 다른거지???)
Experimental Results

이상 끝!!!



