이 논문은 CVPR'23에 publish된 논문으로 2023.12.12 기준 11회의 citation을 보유하고 있다.
Hebbian learning이라는 특이한 기술을 사용해서 early layer의 representation learning을 진행했는데, TENT, DUA, TTT 같은 baseline 을 능가하는 성능을 보였다고 한다. Hebbian이 되게 좋은 아이디어인 것 같고,, TTA 에 두루두루 적용하기에 참 좋은 것 같기는 한데... 내가 Hebbian learning에 대해 가지고 있는 배경지식이 너무 빈약한데에 비해,,, 알고리즘 설명이 너무 불친절하고,, 코드가 안올라와 있어서 (제일 치명적) 이 논문을 내 연구에 적극적으로 반영하긴 힘들듯 하다.. 😥😥
논문은 https://arxiv.org/abs/2303.00914에서 찾아볼 수 있고, 코드는 없다.. 😥😥
Introduction
먼저, 이 논문은 online TTA를 푼다. 저자들에 따르면 기존의 TTA methods 들은 다음의 문제가 존재한다.
(1) early layer representation learning이 잘 되고 있지 않다.
👉 Domain generalization work들에 익숙하다면 잘 알고있겠지만, shallow layer에 style 정보 (domain 정보) 가 존재하고, deep layer에는 비교적 class-specific 정보가 존재한다. 따라서 TTA를 위해서는 early layer에 representation learning을 잘 적용하는게 중요하고,,, 이 논문에서 제안한 Hebbian leraning은 아래 그림과 같이 효과가 좋다.

Hebbian learning. 👉 여기 링크 참고 (https://julien-vitay.net/lecturenotes-neurocomputing/4-neurocomputing/5-Hebbian.html), Hebbian learning은 unsupervised representation learning에 사용될 수 있는 기법으로 뇌과학에서 유래되었다. 실제 뇌에 자극이 들어왔을때 함께 발화된 뉴런들 사이 시냅스가 강화된다는 점에서 영감을 얻어 만들어진 learning method인데,,, Neural network에 적용하면 아래 그림과 같이 두 뉴런 (pre-synaptic, post-synaptic) 의 input과 output 의 크기에 비례해서 그 사이 weight를 update한다.
구체적으로 Neural network을 update하는 방법으로는 covariance-based Hebbian learning, Ora's learning rule, Bienenstock-Cooper-Monroe (BCM) 등 다양한 방법들이 존재한다고 한다.
Method : Neuro-Modulated Hebbian Learning (NHL)
양심선언하자면,,, 개념도 어렵고,, 수식도 어려워서,, 알고리즘 제대로 이해를 못했다. 😥😥
최대한 high-level로 감만 잡을 수 있게 설명해보겠다. (어짜피 코드도 없어서 돌리지도 못하겠지만..)
위 overview figure와 같이 NHL 에는 세가지 구성요소가 있다.
(1) Hebbian layer : early CNN layer이며, Hebbian leraning에 의해 optimize 된다.
(2) Neuromodulator : intermediate CNN layer이며, entropy minimization에 의해 optimize 된다.
(3) Classifier : fixed 되어 훈련되지 않는다.
Feed-Forward Soft Hebbian Learning. 논문에 대한 이해가 부족해.. 아래와 같이 update가 진행된다는 말밖에 해드릴수가 없다.. 🤦♂️🤦♂️🤦♂️🤦♂️. 기본적으로 제안된 알고리즘은 아래 Oja's learning rule을 살짝 변형했다.
👉 xi가 pre-synaptic activation, yk가 post-synaptic activation인데 아래 수식을 보면 −y2k term이 있어,, output signal이 너무 강한 경우에 weight 변화량을 감소시킨다.
이 논문은 위의 learning rule을 아래와 같이 살짝 변형했는데, 솔직히 뭐가 바뀐건지 잘 모르겠다..ㅎㅎ 🤦♂️🤦♂️
R은 normalization 을 위한 power값이고,, uk는 linear layer w를 통과한 output이다.
The NeuroModulation Layer. 위의 Hebbian learning으로 early layer만 훈련시키면 뒤 layer에서 나오는 신호들을 제대로 쓸수가 없어 suboptimal 해진다고 한다. 그래서 TENT 처럼 중간 intermediate layer (neuromodulation layer)를 entropy minimization으로 학습시킨다고 한다...
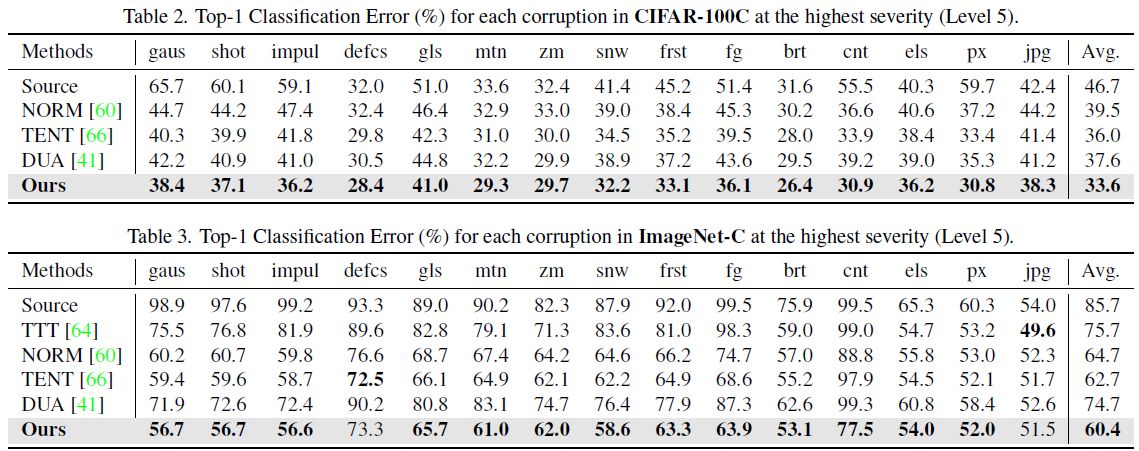
Experimental Results
좀 옛날 baselines 들이긴한데,, 어찌어찌 SoTA를 찍었다고 한다..